The 1.8T (trillion) parameters GPT-MoE might be GPT-4
Jim Fan might have confirmed it.
![]() 3 min. read
3 min. read
![]() Published on
Published on
Share this article

Read our disclosure page to find out how can you help Windows Report sustain the editorial team Read more
At the NVIDIA GTC 2024 event which took place earlier this week, NVIDIA CEO Jensen Huang had a lot to say about the future of AI.
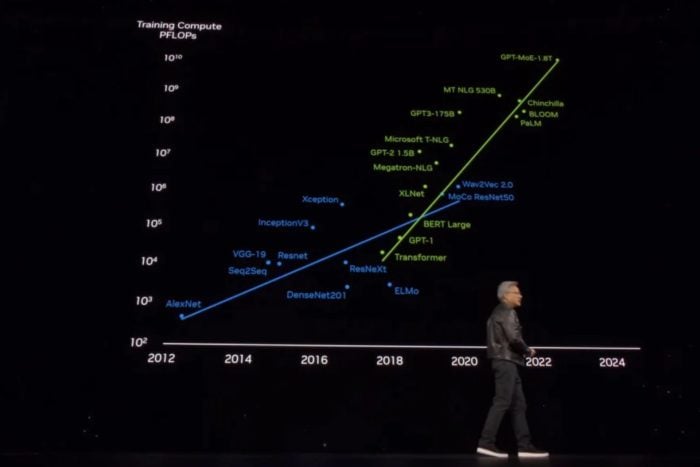
His keynote presentation might have revealed (although by accident) that the largest AI model has a size of a staggering 1.8T (trillion) parameters. It is a GPT-MoE, which many believe might actually be GPT-4.
The MoE (Mixture of Experts) models are known for their capacity to solve intricate, yet varied tasks because they employ a mixture of experts in the form of specific neural networks specialized in solving a certain kind of task (think of mathematics or linguistics).
Such an AI model would be formed of all of these different expert neural networks capable of solving a different array of tasks with formidable expertise. Think of it as an amalgam of different AI models into one. Obviously, the MoE models are quite large. For instance, the recent Mixtral 8x7B leverages up to 45 billion parameters.
However, it pales compared to the GPT-MoE model which is arguably the biggest in the world with a staggering number of 1.8T parameters, or about 1800 billion parameters, to put into perspective.
Huang talked about AI models and mentioned the 1.8 T GPT-MoE in his presentation, placing it at the top of the scale, as you can see in the feature image above. Of course, following the presentation, many started to guess which model is the 1.8 T GPT-MoE, and many believe that it might actually be GPT-4.
Back in 2023, a report from Semyanalysis leaked information about GPT-4 saying that the model is capable of leveraging around 1.8T parameters, across 120 layers, with 16 experts within the model, each leveraging with ~111B parameters. However, OpenAI never confirmed it, but it didn’t deny it either.
But someone else might have confirmed that the 1.8T parameters GPT-MoE is indeed GPT-4, and it is none other than OpenAI’s first intern, Jim Fan, Research Manager, and Lead of Embodied AI. In an X post (formerly known as Twitter) Fan said:
Blackwell, the new beast in town.
> DGX Grace-Blackwell GB200: exceeding 1 Exaflop compute in a single rack.
> Put numbers in perspective: the first DGX that Jensen delivered to OpenAI was 0.17 Petaflops.
> GPT-4-1.8T parameters can finish training in 90 days on 2000 Blackwells.
> New Moore’s law is born.
Jim Fan
However, it might also be the next GPT. Maybe GPT-5? GPT-4 is already 1 year old, so for some users, the model is already old news, even though GPT-4 Turbo has only recently been made available to Copilot.
What do you think?
The 2 hours keynote presentation can be watched in its entirety below: